Demonstrating Hadamard langevin
[1]:
import numpy as np
from context import samplers as samplers
import matplotlib.pyplot as plt
Create matrix \(A\in \mathbb{R}^{m\times p}\) and measurements \(y\in\mathbb{R}^n\). We will sample from
\[\pi\propto \exp\left(-\beta\left(\lambda \|x\|_1 + \frac12\|Ax-y\|^2\right)\right)\]
where \(\lambda>0\) and \(\beta>0\).
[2]:
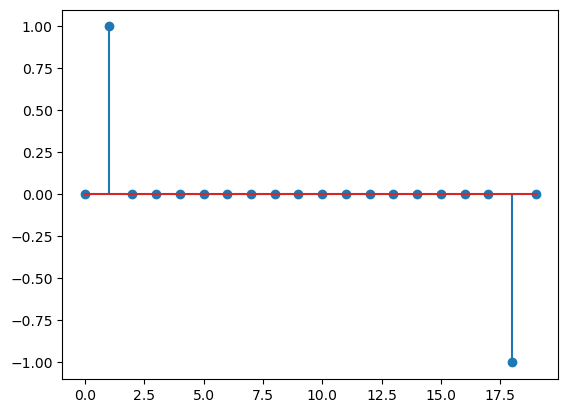
p = 20#signal dimension
m = 40 #number of measurements
#make x0 sparse
x0 = np.sign(np.random.randn(p,))
x0[np.random.permutation(p)[:9*p//10] ]=np.zeros(9*p//10,)
plt.stem(x0)
A = np.random.randn(m,p)/np.sqrt(m)/4
# A = np.array([[1,2]]).T
# print(A)
y = A@x0
lam = np.max(np.abs(A.T@y))*.1
# lam = .5
beta = 5.
print('lambda ', lam, ', beta ', beta)
#smooth part of log density and its gradient
fval = lambda x: np.linalg.norm(A@x - y)**2 * 0.5
grad = lambda x: A.T@(A@x - y)
lambda 0.005524786083441602 , beta 5.0
Proximal Langevin
[3]:
import time
#Lipschitz constant of smooth part
Lf = np.linalg.norm(A.T@A, 2)
#parameter for moreau envelope regularization
gamma= 1/Lf/5
# gamma= 1/Lf/100
#stepsize
tau = gamma/5/(Lf*gamma+1)
print(tau)
# We will record the results in the following lists
method_list = []
sample_list = []
time_list = []
#number of samples and burn in
n_exp = 5
m_exp = 4
n = 10**n_exp #number of samples to generate
burn_in = 10**m_exp #number of burn in samples
0.1928833042471887
[4]:
#defined the gradient of Moreau-envelope of the density
def soft(x,tau):
return np.sign(x)*np.maximum(np.abs(x)-tau,0)
grad_F = lambda x: grad(x) + (x - soft(x,lam*gamma))/gamma
#Run proximal langevin
print('Running prox-l1 sampler ...\n')
name = 'Prox-l1'
Iterate = lambda x: samplers.one_step_langevin(x,p, grad_F, tau,beta)
xinit = np.random.randn(p,)
t1 = time.time()
samples_proxl1 = samplers.generate_samples_x(Iterate, xinit, n, burn_in)
time_list.append(time.time()-t1)
method_list.append(name)
sample_list.append(samples_proxl1)
Running prox-l1 sampler ...
[79]:
#Run proximal langevin with metropolis hastings correction
print('Running Proxl1 MALA sampler ...\n')
name = 'proxl1-MALA'
Iterate = lambda x: samplers.one_step_MALA(x, p, lambda x: fval(x) + lam*np.sum(np.abs(x)), grad_F, tau,beta)
t1 = time.time()
samples_px_mala = samplers.generate_samples_x(Iterate, xinit, n, burn_in)
time_list.append(time.time()-t1)
method_list.append(name)
sample_list.append(samples_px_mala)
Running Proxl1 MALA sampler ...
Hadamard Langevin
[5]:
n = 10**n_exp #number of samples to generate
burn_in = 10**m_exp #number of burn in samples
#we will use the same stepsize as for proximal langevin
print('Running Hadamard sampler ... \n')
name = 'Hadamard'
Iterate = lambda x: samplers.one_step_hadamard(x, p,grad, tau, lam,beta)
#initialization
uinit = np.random.rand(p,)
vinit = np.random.randn(p,)
uvinit = np.concatenate((uinit,vinit))
t1 = time.time()
samples_uv = samplers.generate_samples_x(Iterate, uvinit, n, burn_in)
#take the Hadamard product for samples to the required density
samples_x_uv = samples_uv[:,:p]*samples_uv[:,p:]
time_list.append(time.time()-t1)
method_list.append(name)
sample_list.append(samples_x_uv)
Running Hadamard sampler ...
[25]:
#Overparameterized langevin with metropolis hastings
print('Running Hadamard MALA sampler ...\n')
name = 'Hadamard-MALA'
Iterate = lambda x: samplers.one_step_MALA_hadamard(x,p, fval, grad, tau, lam,beta)
uvinit = np.concatenate((uinit,vinit))
t1 = time.time()
samples_uv_mala = samplers.generate_samples_x(Iterate, uvinit, n, burn_in)
samples_x_mala = samples_uv_mala[:,:p]*samples_uv_mala[:,p:]
time_list.append(time.time()-t1)
method_list.append(name)
sample_list.append(samples_x_mala)
Running Hadamard MALA sampler ...
Running the Gibbs sampler
[6]:
print('Running Gibbs sampler ... \n')
name = 'Gibbs'
n = 10**(n_exp-1) #number of samples to generate
burn_in = 10**(m_exp-3) #number of burn in samples
init = np.ones(p,)
t1 = time.time()
gibbs_x_samples = samplers.gibbs_sampler(A,y, lam,init, n, burn_in=burn_in, beta=beta)
# gibbs_x_samples = gibbs_samples[:,:p]
time_list.append(time.time()-t1)
method_list.append(name)
sample_list.append(gibbs_x_samples)
Running Gibbs sampler ...
Visualize the results
[15]:
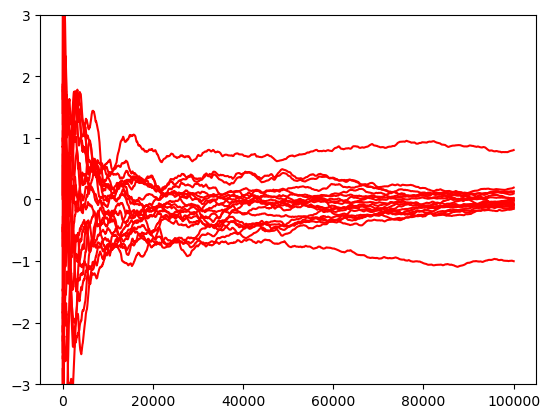
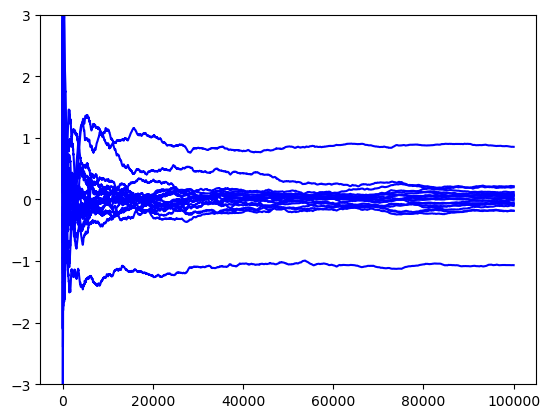
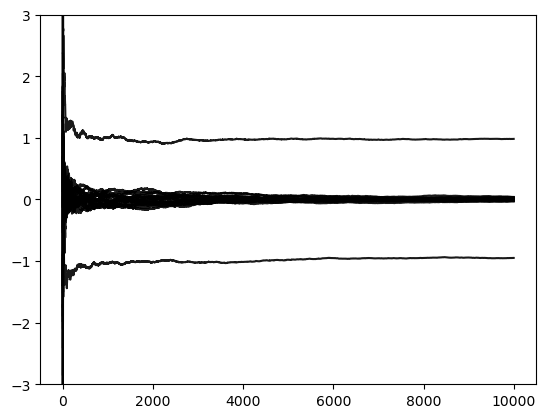
# Plot the running means
M = len(method_list)
from itertools import cycle
colours = cycle(['red', 'blue', 'black', 'orange','yellow','orange'])
# mean_true = integrate.quad(lambda x: x**2*f(x), -np.inf, np.inf)[0]/Total_mass
for i in range(M):
samples = sample_list[i]
name = method_list[i]
running_mean = np.cumsum(samples, axis=0) / (np.arange(len(samples))[:, None] + 1)
c = next(colours)
print(name)
if i<M-1:
plt.plot(running_mean,color = c,label=name,alpha=1)
else:
plt.plot(running_mean,color = c,label=name,alpha=.9)
plt.ylim([-3,3])
plt.savefig('results/'+name+'means.pdf', bbox_inches='tight')
plt.show()
# plt.legend()
# plt.xlim([0,4000])
# plt.show()
# plt.savefig('results/means.pdf', bbox_inches='tight')
Prox-l1
Hadamard
Gibbs
Check the effective sample size
[28]:
#effective sample size
import numpy as np
import arviz as az
import matplotlib.pyplot as plt
# Compute Effective Sample Size (ESS)
idata_list = []
ess_list= []
for samples in sample_list:
idata = az.convert_to_inference_data(np.expand_dims(samples, 0))
idata_list.append(idata)
ess_list.append(az.ess(idata))
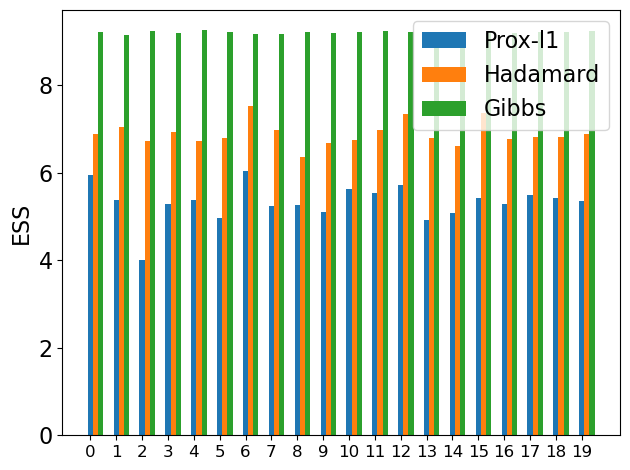
# Visualization
labels = [str(i) for i in range(p)]
fig, ax = plt.subplots()
M = len(method_list)
width = 0.2 # the width of the bars
x = np.arange(p)-width
for i in range(M):
ess_values = np.log(ess_list[i]['x'].values)
rects1 = ax.bar(x +i*width, ess_values, width, label=method_list[i])
# # Add some text for labels, title, and custom x-axis tick labels, etc.
ax.set_ylabel('ESS',fontsize=16)
# ax.set_title('Effective Sample Size by Algorithm and dimension')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend(fontsize=16)
ax.tick_params(axis='x', labelsize=12)
ax.tick_params(axis='y', labelsize=16)
fig.tight_layout()
plt.savefig('results/ESS.pdf', bbox_inches='tight')
# plt.xlabel('Dimension')
plt.show()
#display minimum ess
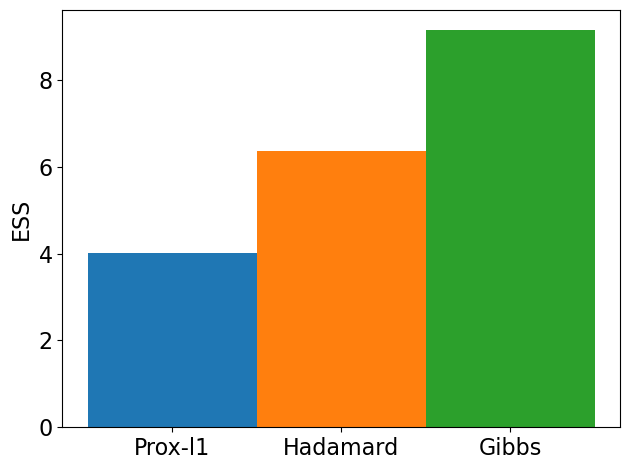
# Visualization
if p>1:
labels = [str(i) for i in range(p)]
fig, ax = plt.subplots()
M = len(method_list)
width = 0.2 # the width of the bars
x = np.arange(1)-width
xticks=[]
for i in range(M):
print(method_list[i])
ess_values = np.log((ess_list[i]['x'].values).min())
print(ess_values)
rects1 = ax.bar(x +i*width, ess_values, width, label=method_list[i])
xticks.append(x[0] +i*width)
ax.set_ylabel('ESS',fontsize=16)
# ax.set_title('Minimum Effective Sample Size by Algorithm')
ax.set_xticks(xticks)
ax.set_xticklabels(method_list,fontsize=16)
ax.tick_params(axis='x', labelsize=16)
ax.tick_params(axis='y', labelsize=16)
fig.tight_layout()
plt.savefig('results/ESS_min.pdf', bbox_inches='tight')
# plt.xlabel('Dimension')
plt.show()
Prox-l1
4.005851575122584
Hadamard
6.36752302816277
Gibbs
9.155003688288497
Plot the densities if in dimension 1 or 2
[198]:
from scipy import integrate
#For dimension p=1 and p=2, get true density via numerical integration
if p==1:
def f(x):
return np.exp(-(fval(np.array([x]))+lam*np.abs(x))*beta)
Total_mass = integrate.quad(f, -np.inf, np.inf)[0]
# print(Total_mass)
density = lambda x: f(x)/Total_mass
mean_true = integrate.quad(lambda x: x*f(x), -np.inf, np.inf)[0]/Total_mass
def rho(xgrid):
return np.array([density(t) for t in xgrid])
if p==2:
def f(x1,x2):
return np.exp(-beta*( fval(np.array([x1,x2]))+lam*np.abs(x1)-lam*np.abs(x2)) )
Total_mass = integrate.dblquad(f, -np.inf, np.inf, -np.inf, np.inf)[0]
density = lambda x1,x2: f(x1,x2)/Total_mass
mean_true = integrate.dblquad(lambda x1,x2: x1**2*f(x1,x2), -np.inf, np.inf, -np.inf, np.inf)[0]/Total_mass
def rho(xgrid,ygrid):
return np.array([density(t,s) for t in xgrid for s in ygrid])
[ ]:
import matplotlib.pyplot as plt
from scipy.special import kl_div as kl
from matplotlib import cm
#functions to evaluate the KL error in diemnsion p=1 and p=2
def KL_error(samples, rho, plot=True):
counts, bins = np.histogram(samples,100,density=True)
xgrid = (bins[1:] + bins[:-1])/2
if plot:
plt.plot(xgrid, counts)
xgrid_fine = np.linspace(min(bins), max(bins),1000)
plt.plot(xgrid_fine,rho(xgrid_fine), 'r--')
return np.sum(kl(counts,rho(xgrid)))
def KL_error_2d(samples, rho, plot=True):
Z, xbins,ybins = np.histogram2d(samples[:,0], samples[:,1],bins=100,density=True)
xgrid = (xbins[1:] + xbins[:-1])/2
ygrid = (ybins[1:] + ybins[:-1])/2
Z2 = rho(xgrid,ygrid)
if plot:
ax = plt.figure().add_subplot(projection='3d')
X,Y = np.meshgrid(xgrid,ygrid)
surf = ax.plot_surface(X, Y, Z, alpha=0.8, cmap = cm.coolwarm,
linewidth=0, antialiased=False)
surf2 = ax.plot_surface(X, Y, Z2.reshape(len(xgrid),len(ygrid)), alpha=0.1, cmap = cm.jet,
linewidth=0, antialiased=False)
# ax.set(xlim=[-20, 20], ylim=[-5, 15])
return np.sum(kl(Z.reshape(-1),Z2))/len(Z2)
[ ]:
print(time_list)
colors = ['k--','k', 'g--', 'g', 'm']
print('Compute errors and plot (p<=2 only) ...\n')
if p==1:
def get_running_error(samples, rho):
error_list = []
skip = len(samples)//50
for i in range(100,len(samples),skip):
error = KL_error(samples[:i],rho,plot=False)
error_list.append(error)
return error_list
def get_running_mean_error(samples, rho):
error_list = []
skip = len(samples)//50
for i in range(100,len(samples),skip):
error = np.abs(np.mean(samples[:i])-mean_true)
error_list.append(error)
return error_list
error_list = []
for samples,name,t in zip(sample_list,method_list,time_list):
error_list.append(get_running_error(samples, rho))
for errors, name,t, c in zip(error_list,method_list,time_list,colors):
plt.semilogy(np.linspace(0,t,len(errors)), errors,c, label=name)
plt.legend()
plt.savefig('results/Error_Time.pdf', bbox_inches='tight')
plt.title('KL error against time')
plt.show()
for i in range(len(sample_list)):
S = len(sample_list[i])
errors= error_list[i]
name = method_list[i]
plt.semilogy(np.linspace(0,S,len(errors)), errors,colors[i], label=name)
plt.legend()
plt.savefig('results/Error.pdf', bbox_inches='tight')
plt.title('KL error against iteration')
plt.show()
for samples,name in zip(sample_list,method_list):
print('Error ',name, ' :', KL_error(samples,rho,plot=True))
# plt.xlim([-5,5])
plt.savefig('results/density-'+name+'.pdf', bbox_inches='tight')
plt.title(name)
plt.show()
elif p==2:
def get_running_error(samples, rho):
error_list = []
skip = len(samples)//20
for i in range(100,len(samples),skip):
error = KL_error_2d(samples[:i,:],rho,plot=False)
error_list.append(error)
return error_list
error_list = []
for samples,name,t in zip(sample_list,method_list,time_list):
error_list.append(get_running_error(samples, rho))
for errors, name,t in zip(error_list,method_list,time_list):
plt.semilogy(np.linspace(0,t,len(errors)), errors, label=name)
plt.legend()
plt.savefig('results/Error_Time.pdf', bbox_inches='tight')
plt.show()
for i in range(len(sample_list)):
S = len(sample_list[i])
errors= error_list[i]
name = method_list[i]
plt.semilogy(np.linspace(0,S,len(errors)), errors, label=name)
plt.legend()
plt.savefig('results/Error.pdf', bbox_inches='tight')
plt.show()
[ ]:
[ ]:
[ ]:
[ ]:
[ ]:
[ ]: